Video and Live-Feed Detection and Analysis¶
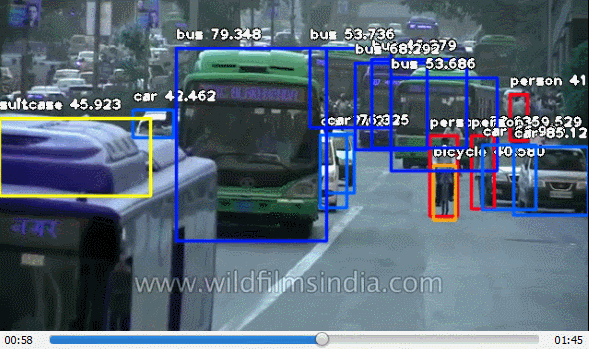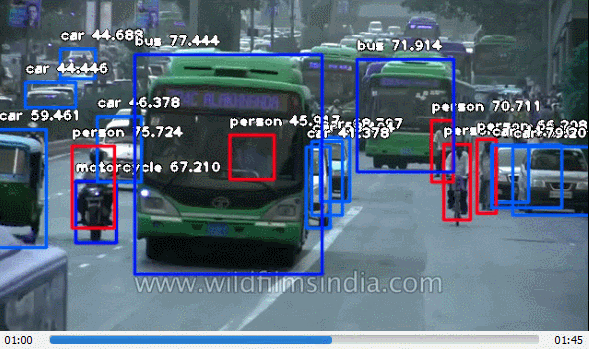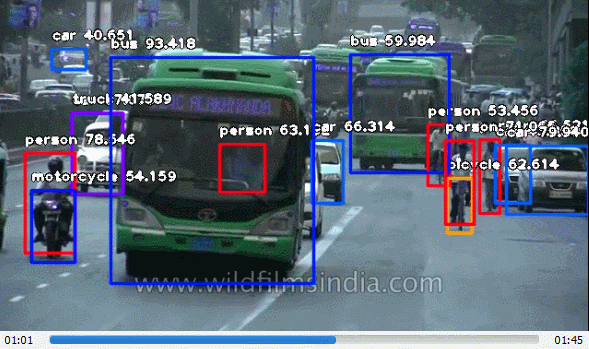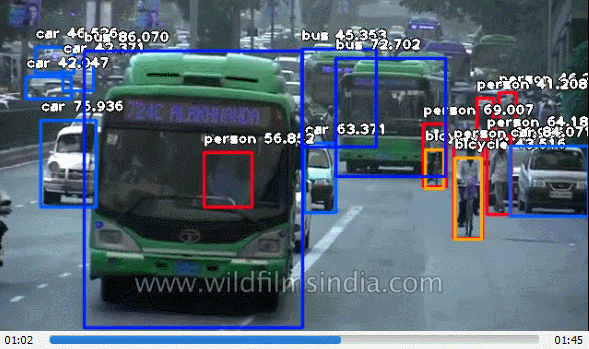
ImageAI provided very powerful yet easy to use classes and functions to perform Video Object Detection and Tracking and Video analysis. ImageAI allows you to perform all of these with state-of-the-art deep learning algorithms like RetinaNet, YOLOv3 and TinyYOLOv3. With ImageAI you can run detection tasks and analyse videos and live-video feeds from device cameras and IP cameras. Find below the classes and their respective functions available for you to use. These classes can be integrated into any traditional python program you are developing, be it a website, Windows/Linux/MacOS application or a system that supports or part of a Local-Area-Network.
======= imageai.Detection.VideoObjectDetection =======
This VideoObjectDetection class provides you function to detect objects in videos and live-feed from device cameras and IP cameras, using pre-trained models that was trained on the COCO dataset. The models supported are RetinaNet, YOLOv3 and TinyYOLOv3. This means you can detect and recognize 80 different kind of common everyday objects in any video. To get started, download any of the pre-trained model that you want to use via the links below.
Download RetinaNet Model - retinanet_resnet50_fpn_coco-eeacb38b.pth
Download YOLOv3 Model - yolov3.pt
Download TinyYOLOv3 Model - tiny-yolov3.pt
Once you have downloaded the model you chose to use, create an instance of the VideoObjectDetection as seen below:
from imageai.Detection import VideoObjectDetection
detector = VideoObjectDetection()
Once you have created an instance of the class, you can call the functions below to set its properties and detect objects in a video.
.setModelTypeAsRetinaNet() , This function sets the model type of the object detection instance you created to the RetinaNet model, which means you will be performing your object detection tasks using the pre-trained “RetinaNet” model you downloaded from the links above. Find example code below:
detector.setModelTypeAsRetinaNet()
.setModelTypeAsYOLOv3() , This function sets the model type of the object detection instance you created to the YOLOv3 model, which means you will be performing your object detection tasks using the pre-trained “YOLOv3” model you downloaded from the links above. Find example code below:
detector.setModelTypeAsYOLOv3()
.setModelTypeAsTinyYOLOv3() , This function sets the model type of the object detection instance you created to the TinyYOLOv3 model, which means you will be performing your object detection tasks using the pre-trained “TinyYOLOv3” model you downloaded from the links above. Find example code below:
detector.setModelTypeAsTinyYOLOv3()
.setModelPath() , This function accepts a string which must be the path to the model file you downloaded and must corresponds to the model type you set for your object detection instance. Find example code,and parameters of the function below:
detector.setModelPath("yolov3.pt")
– parameter model_path (required) : This is the path to your downloaded model file.
.loadModel() , This function loads the model from the path you specified in the function call above into your object detection instance. Find example code below:
detector.loadModel()
– parameter detection_speed (optional) : This parameter allows you to reduce the time it takes to detect objects in a video by up to 80% which leads to slight reduction in accuracy. This parameter accepts string values. The available values are “normal”, “fast”, “faster”, “fastest” and “flash”. The default values is “normal”
.useCPU() , This function loads the model in CPU and forces processes to be done on the CPU. This is because by default, ImageAI will use GPU/CUDA if available else default to CPU. Find example code:
detector.useCPU()
.detectObjectsFromVideo() , This is the function that performs object detecttion on a video file or video live-feed after the model has been loaded into the instance you created. Find a full sample code below:
from imageai.Detection import VideoObjectDetection import os execution_path = os.getcwd() detector = VideoObjectDetection() detector.setModelTypeAsYOLOv3() detector.setModelPath( os.path.join(execution_path , "yolov3.pt")) detector.loadModel() video_path = detector.detectObjectsFromVideo(input_file_path=os.path.join(execution_path, "traffic.mp4"), output_file_path=os.path.join(execution_path, "traffic_detected") , frames_per_second=20, log_progress=True) print(video_path)
– parameter input_file_path (required if you did not set camera_input) : This refers to the path to the video file you want to detect.
—parameter output_file_path (required if you did not set save_detected_video = False) : This refers to the path to which the detected video will be saved. By default, this functionsaves video .avi format.
– parameter frames_per_second (optional , but recommended) : This parameters allows you to set your desired frames per second for the detected video that will be saved. The default value is 20 but we recommend you set the value that suits your video or camera live-feed.
—parameter log_progress (optional) : Setting this parameter to True shows the progress of the video or live-feed as it is detected in the CLI. It will report every frame detected as it progresses. The default value is False.
– parameter return_detected_frame (optional) : This parameter allows you to return the detected frame as a Numpy array at every frame, second and minute of the video detected. The returned Numpy array will be parsed into the respective per_frame_function, per_second_function and per_minute_function (See details below)
—parameter camera_input (optional) : This parameter can be set in replacement of the input_file_path if you want to detect objects in the live-feed of a camera. All you need is to load the camera with OpenCV’s VideoCapture() function and parse the object into this parameter.
See a full code sample below:
from imageai.Detection import VideoObjectDetection import os import cv2 execution_path = os.getcwd() camera = cv2.VideoCapture(0) detector = VideoObjectDetection() detector.setModelTypeAsYOLOv3() detector.setModelPath(os.path.join(execution_path , "yolov3.pt")) detector.loadModel() video_path = detector.detectObjectsFromVideo(camera_input=camera, output_file_path=os.path.join(execution_path, "camera_detected_video") , frames_per_second=20, log_progress=True, minimum_percentage_probability=30) print(video_path)—parameter minimum_percentage_probability (optional ) : This parameter is used to determine the integrity of the detection results. Lowering the value shows more objects while increasing the value ensures objects with the highest accuracy are detected. The default value is 50.
– parameter display_percentage_probability (optional ) : This parameter can be used to hide the percentage probability of each object detected in the detected video if set to False. The default values is True.
—parameter display_object_name (optional ) : This parameter can be used to hide the name of each object detected in the detected video if set to False. The default values is True.
– parameter save_detected_video (optional ) : This parameter can be used to or not to save the detected video or not to save it. It is set to True by default.
—parameter per_frame_function (optional ) : This parameter allows you to parse in the name of a function you define. Then, for every frame of the video that is detected, the function will be parsed into the parameter will be executed and and analytical data of the video will be parsed into the function. The data returned can be visualized or saved in a NoSQL database for future processing and visualization.
See the sample code below:
""" This parameter allows you to parse in a function you will want to execute after each frame of the video is detected. If this parameter is set to a function, after every video frame is detected, the function will be executed with the following values parsed into it: -- position number of the frame -- an array of dictinaries, with each dictinary corresponding to each object detected. Each dictionary contains 'name', 'percentage_probability' and 'box_points' -- a dictionary with with keys being the name of each unique objects and value are the number of instances of each of the objects present -- If return_detected_frame is set to True, the numpy array of the detected frame will be parsed as the fourth value into the function """ from imageai.Detection import VideoObjectDetection import os def forFrame(frame_number, output_array, output_count): print("FOR FRAME " , frame_number) print("Output for each object : ", output_array) print("Output count for unique objects : ", output_count) print("------------END OF A FRAME --------------") video_detector = VideoObjectDetection() video_detector.setModelTypeAsYOLOv3() video_detector.setModelPath(os.path.join(execution_path, "yolov3.pt")) video_detector.loadModel() video_detector.detectObjectsFromVideo(input_file_path=os.path.join(execution_path, "traffic.mp4"), output_file_path=os.path.join(execution_path, "video_frame_analysis") , frames_per_second=20, per_frame_function=forFrame, minimum_percentage_probability=30)In the above example, once every frame in the video is processed and detected, the function will receive and prints out the analytical data for objects detected in the video frame as you can see below:
Output for each object : [{'box_points': (362, 295, 443, 355), 'name': 'boat', 'percentage_probability': 26.666194200515747}, {'box_points': (319, 245, 386, 296), 'name': 'boat', 'percentage_probability': 30.052968859672546}, {'box_points': (219, 308, 341, 358), 'name': 'boat', 'percentage_probability': 47.46982455253601}, {'box_points': (589, 198, 621, 241), 'name': 'bus', 'percentage_probability': 24.62330162525177}, {'box_points': (519, 181, 583, 263), 'name': 'bus', 'percentage_probability': 27.446213364601135}, {'box_points': (493, 197, 561, 272), 'name': 'bus', 'percentage_probability': 59.81815457344055}, {'box_points': (432, 187, 491, 240), 'name': 'bus', 'percentage_probability': 64.42965269088745}, {'box_points': (157, 225, 220, 255), 'name': 'car', 'percentage_probability': 21.150341629981995}, {'box_points': (324, 249, 377, 293), 'name': 'car', 'percentage_probability': 24.089913070201874}, {'box_points': (152, 275, 260, 327), 'name': 'car', 'percentage_probability': 30.341443419456482}, {'box_points': (433, 198, 485, 244), 'name': 'car', 'percentage_probability': 37.205660343170166}, {'box_points': (184, 226, 233, 260), 'name': 'car', 'percentage_probability': 38.52525353431702}, {'box_points': (3, 296, 134, 359), 'name': 'car', 'percentage_probability': 47.80363142490387}, {'box_points': (357, 302, 439, 359), 'name': 'car', 'percentage_probability': 47.94844686985016}, {'box_points': (481, 266, 546, 314), 'name': 'car', 'percentage_probability': 65.8585786819458}, {'box_points': (597, 269, 624, 318), 'name': 'person', 'percentage_probability': 27.125394344329834}] Output count for unique objects : {'bus': 4, 'boat': 3, 'person': 1, 'car': 8} ------------END OF A FRAME --------------Below is a full code that has a function that taskes the analyitical data and visualizes it and the detected frame in real time as the video is processed and detected:
from imageai.Detection import VideoObjectDetection import os from matplotlib import pyplot as plt execution_path = os.getcwd() color_index = {'bus': 'red', 'handbag': 'steelblue', 'giraffe': 'orange', 'spoon': 'gray', 'cup': 'yellow', 'chair': 'green', 'elephant': 'pink', 'truck': 'indigo', 'motorcycle': 'azure', 'refrigerator': 'gold', 'keyboard': 'violet', 'cow': 'magenta', 'mouse': 'crimson', 'sports ball': 'raspberry', 'horse': 'maroon', 'cat': 'orchid', 'boat': 'slateblue', 'hot dog': 'navy', 'apple': 'cobalt', 'parking meter': 'aliceblue', 'sandwich': 'skyblue', 'skis': 'deepskyblue', 'microwave': 'peacock', 'knife': 'cadetblue', 'baseball bat': 'cyan', 'oven': 'lightcyan', 'carrot': 'coldgrey', 'scissors': 'seagreen', 'sheep': 'deepgreen', 'toothbrush': 'cobaltgreen', 'fire hydrant': 'limegreen', 'remote': 'forestgreen', 'bicycle': 'olivedrab', 'toilet': 'ivory', 'tv': 'khaki', 'skateboard': 'palegoldenrod', 'train': 'cornsilk', 'zebra': 'wheat', 'tie': 'burlywood', 'orange': 'melon', 'bird': 'bisque', 'dining table': 'chocolate', 'hair drier': 'sandybrown', 'cell phone': 'sienna', 'sink': 'coral', 'bench': 'salmon', 'bottle': 'brown', 'car': 'silver', 'bowl': 'maroon', 'tennis racket': 'palevilotered', 'airplane': 'lavenderblush', 'pizza': 'hotpink', 'umbrella': 'deeppink', 'bear': 'plum', 'fork': 'purple', 'laptop': 'indigo', 'vase': 'mediumpurple', 'baseball glove': 'slateblue', 'traffic light': 'mediumblue', 'bed': 'navy', 'broccoli': 'royalblue', 'backpack': 'slategray', 'snowboard': 'skyblue', 'kite': 'cadetblue', 'teddy bear': 'peacock', 'clock': 'lightcyan', 'wine glass': 'teal', 'frisbee': 'aquamarine', 'donut': 'mincream', 'suitcase': 'seagreen', 'dog': 'springgreen', 'banana': 'emeraldgreen', 'person': 'honeydew', 'surfboard': 'palegreen', 'cake': 'sapgreen', 'book': 'lawngreen', 'potted plant': 'greenyellow', 'toaster': 'ivory', 'stop sign': 'beige', 'couch': 'khaki'} resized = False def forFrame(frame_number, output_array, output_count, returned_frame): plt.clf() this_colors = [] labels = [] sizes = [] counter = 0 for eachItem in output_count: counter += 1 labels.append(eachItem + " = " + str(output_count[eachItem])) sizes.append(output_count[eachItem]) this_colors.append(color_index[eachItem]) global resized if (resized == False): manager = plt.get_current_fig_manager() manager.resize(width=1000, height=500) resized = True plt.subplot(1, 2, 1) plt.title("Frame : " + str(frame_number)) plt.axis("off") plt.imshow(returned_frame, interpolation="none") plt.subplot(1, 2, 2) plt.title("Analysis: " + str(frame_number)) plt.pie(sizes, labels=labels, colors=this_colors, shadow=True, startangle=140, autopct="%1.1f%%") plt.pause(0.01) video_detector = VideoObjectDetection() video_detector.setModelTypeAsYOLOv3() video_detector.setModelPath(os.path.join(execution_path, "yolov3.pt")) video_detector.loadModel() plt.show() video_detector.detectObjectsFromVideo(input_file_path=os.path.join(execution_path, "traffic.mp4"), output_file_path=os.path.join(execution_path, "video_frame_analysis") , frames_per_second=20, per_frame_function=forFrame, minimum_percentage_probability=30, return_detected_frame=True)—parameter per_second_function (optional ) : This parameter allows you to parse in the name of a function you define. Then, for every second of the video that is detected, the function will be parsed into the parameter will be executed and analytical data of the video will be parsed into the function. The data returned can be visualized or saved in a NoSQL database for future processing and visualization.
See the sample code below:
""" This parameter allows you to parse in a function you will want to execute after each second of the video is detected. If this parameter is set to a function, after every second of a video is detected, the function will be executed with the following values parsed into it: -- position number of the second -- an array of dictionaries whose keys are position number of each frame present in the last second , and the value for each key is the array for each frame that contains the dictionaries for each object detected in the frame -- an array of dictionaries, with each dictionary corresponding to each frame in the past second, and the keys of each dictionary are the name of the number of unique objects detected in each frame, and the key values are the number of instances of the objects found in the frame -- a dictionary with its keys being the name of each unique object detected throughout the past second, and the key values are the average number of instances of the object found in all the frames contained in the past second -- If return_detected_frame is set to True, the numpy array of the detected frame will be parsed as the fifth value into the function """ from imageai.Detection import VideoObjectDetection import os def forSeconds(second_number, output_arrays, count_arrays, average_output_count): print("SECOND : ", second_number) print("Array for the outputs of each frame ", output_arrays) print("Array for output count for unique objects in each frame : ", count_arrays) print("Output average count for unique objects in the last second: ", average_output_count) print("------------END OF A SECOND --------------") video_detector = VideoObjectDetection() video_detector.setModelTypeAsYOLOv3() video_detector.setModelPath(os.path.join(execution_path, "yolov3.pt")) video_detector.loadModel() video_detector.detectObjectsFromVideo(input_file_path=os.path.join(execution_path, "traffic.mp4"), output_file_path=os.path.join(execution_path, "video_second_analysis") , frames_per_second=20, per_second_function=forSecond, minimum_percentage_probability=30)In the above example, once every second in the video is processed and detected, the function will receive and prints out the analytical data for objects detected in the video as you can see below:
Array for the outputs of each frame [[{'box_points': (362, 295, 443, 355), 'name': 'boat', 'percentage_probability': 26.666194200515747}, {'box_points': (319, 245, 386, 296), 'name': 'boat', 'percentage_probability': 30.052968859672546}, {'box_points': (219, 308, 341, 358), 'name': 'boat', 'percentage_probability': 47.46982455253601}, {'box_points': (589, 198, 621, 241), 'name': 'bus', 'percentage_probability': 24.62330162525177}, {'box_points': (519, 181, 583, 263), 'name': 'bus', 'percentage_probability': 27.446213364601135}, {'box_points': (493, 197, 561, 272), 'name': 'bus', 'percentage_probability': 59.81815457344055}, {'box_points': (432, 187, 491, 240), 'name': 'bus', 'percentage_probability': 64.42965269088745}, {'box_points': (157, 225, 220, 255), 'name': 'car', 'percentage_probability': 21.150341629981995}, {'box_points': (324, 249, 377, 293), 'name': 'car', 'percentage_probability': 24.089913070201874}, {'box_points': (152, 275, 260, 327), 'name': 'car', 'percentage_probability': 30.341443419456482}, {'box_points': (433, 198, 485, 244), 'name': 'car', 'percentage_probability': 37.205660343170166}, {'box_points': (184, 226, 233, 260), 'name': 'car', 'percentage_probability': 38.52525353431702}, {'box_points': (3, 296, 134, 359), 'name': 'car', 'percentage_probability': 47.80363142490387}, {'box_points': (357, 302, 439, 359), 'name': 'car', 'percentage_probability': 47.94844686985016}, {'box_points': (481, 266, 546, 314), 'name': 'car', 'percentage_probability': 65.8585786819458}, {'box_points': (597, 269, 624, 318), 'name': 'person', 'percentage_probability': 27.125394344329834}], [{'box_points': (316, 240, 384, 302), 'name': 'boat', 'percentage_probability': 29.594269394874573}, {'box_points': (361, 295, 441, 354), 'name': 'boat', 'percentage_probability': 36.11513376235962}, {'box_points': (216, 305, 340, 357), 'name': 'boat', 'percentage_probability': 44.89373862743378}, {'box_points': (432, 198, 488, 244), 'name': 'truck', 'percentage_probability': 22.914741933345795}, {'box_points': (589, 199, 623, 240), 'name': 'bus', 'percentage_probability': 20.545457303524017}, {'box_points': (519, 182, 583, 263), 'name': 'bus', 'percentage_probability': 24.467085301876068}, {'box_points': (492, 197, 563, 271), 'name': 'bus', 'percentage_probability': 61.112016439437866}, {'box_points': (433, 188, 490, 241), 'name': 'bus', 'percentage_probability': 65.08989334106445}, {'box_points': (352, 303, 442, 357), 'name': 'car', 'percentage_probability': 20.025095343589783}, {'box_points': (136, 172, 188, 195), 'name': 'car', 'percentage_probability': 21.571354568004608}, {'box_points': (152, 276, 261, 326), 'name': 'car', 'percentage_probability': 33.07966589927673}, {'box_points': (181, 225, 230, 256), 'name': 'car', 'percentage_probability': 35.111838579177856}, {'box_points': (432, 198, 488, 244), 'name': 'car', 'percentage_probability': 36.25282347202301}, {'box_points': (3, 292, 130, 360), 'name': 'car', 'percentage_probability': 67.55480170249939}, {'box_points': (479, 265, 546, 314), 'name': 'car', 'percentage_probability': 71.47912979125977}, {'box_points': (597, 269, 625, 318), 'name': 'person', 'percentage_probability': 25.903674960136414}],................, [{'box_points': (133, 250, 187, 278), 'name': 'umbrella', 'percentage_probability': 21.518094837665558}, {'box_points': (154, 233, 218, 259), 'name': 'umbrella', 'percentage_probability': 23.687003552913666}, {'box_points': (348, 311, 425, 360), 'name': 'boat', 'percentage_probability': 21.015766263008118}, {'box_points': (11, 164, 137, 225), 'name': 'bus', 'percentage_probability': 32.20453858375549}, {'box_points': (424, 187, 485, 243), 'name': 'bus', 'percentage_probability': 38.043853640556335}, {'box_points': (496, 186, 570, 264), 'name': 'bus', 'percentage_probability': 63.83994221687317}, {'box_points': (588, 197, 622, 240), 'name': 'car', 'percentage_probability': 23.51653128862381}, {'box_points': (58, 268, 111, 303), 'name': 'car', 'percentage_probability': 24.538707733154297}, {'box_points': (2, 246, 72, 301), 'name': 'car', 'percentage_probability': 28.433072566986084}, {'box_points': (472, 273, 539, 323), 'name': 'car', 'percentage_probability': 87.17672824859619}, {'box_points': (597, 270, 626, 317), 'name': 'person', 'percentage_probability': 27.459821105003357}] ] Array for output count for unique objects in each frame : [{'bus': 4, 'boat': 3, 'person': 1, 'car': 8}, {'truck': 1, 'bus': 4, 'boat': 3, 'person': 1, 'car': 7}, {'bus': 5, 'boat': 2, 'person': 1, 'car': 5}, {'bus': 5, 'boat': 1, 'person': 1, 'car': 9}, {'truck': 1, 'bus': 2, 'car': 6, 'person': 1}, {'truck': 2, 'bus': 4, 'boat': 2, 'person': 1, 'car': 7}, {'truck': 1, 'bus': 3, 'car': 7, 'person': 1, 'umbrella': 1}, {'bus': 4, 'car': 7, 'person': 1, 'umbrella': 2}, {'bus': 3, 'car': 6, 'boat': 1, 'person': 1, 'umbrella': 3}, {'bus': 3, 'car': 4, 'boat': 1, 'person': 1, 'umbrella': 2}] Output average count for unique objects in the last second: {'truck': 0.5, 'bus': 3.7, 'umbrella': 0.8, 'boat': 1.3, 'person': 1.0, 'car': 6.6} ------------END OF A SECOND --------------Below is a full code that has a function that taskes the analyitical data and visualizes it and the detected frame at the end of the second in real time as the video is processed and detected:
from imageai.Detection import VideoObjectDetection import os from matplotlib import pyplot as plt execution_path = os.getcwd() color_index = {'bus': 'red', 'handbag': 'steelblue', 'giraffe': 'orange', 'spoon': 'gray', 'cup': 'yellow', 'chair': 'green', 'elephant': 'pink', 'truck': 'indigo', 'motorcycle': 'azure', 'refrigerator': 'gold', 'keyboard': 'violet', 'cow': 'magenta', 'mouse': 'crimson', 'sports ball': 'raspberry', 'horse': 'maroon', 'cat': 'orchid', 'boat': 'slateblue', 'hot dog': 'navy', 'apple': 'cobalt', 'parking meter': 'aliceblue', 'sandwich': 'skyblue', 'skis': 'deepskyblue', 'microwave': 'peacock', 'knife': 'cadetblue', 'baseball bat': 'cyan', 'oven': 'lightcyan', 'carrot': 'coldgrey', 'scissors': 'seagreen', 'sheep': 'deepgreen', 'toothbrush': 'cobaltgreen', 'fire hydrant': 'limegreen', 'remote': 'forestgreen', 'bicycle': 'olivedrab', 'toilet': 'ivory', 'tv': 'khaki', 'skateboard': 'palegoldenrod', 'train': 'cornsilk', 'zebra': 'wheat', 'tie': 'burlywood', 'orange': 'melon', 'bird': 'bisque', 'dining table': 'chocolate', 'hair drier': 'sandybrown', 'cell phone': 'sienna', 'sink': 'coral', 'bench': 'salmon', 'bottle': 'brown', 'car': 'silver', 'bowl': 'maroon', 'tennis racket': 'palevilotered', 'airplane': 'lavenderblush', 'pizza': 'hotpink', 'umbrella': 'deeppink', 'bear': 'plum', 'fork': 'purple', 'laptop': 'indigo', 'vase': 'mediumpurple', 'baseball glove': 'slateblue', 'traffic light': 'mediumblue', 'bed': 'navy', 'broccoli': 'royalblue', 'backpack': 'slategray', 'snowboard': 'skyblue', 'kite': 'cadetblue', 'teddy bear': 'peacock', 'clock': 'lightcyan', 'wine glass': 'teal', 'frisbee': 'aquamarine', 'donut': 'mincream', 'suitcase': 'seagreen', 'dog': 'springgreen', 'banana': 'emeraldgreen', 'person': 'honeydew', 'surfboard': 'palegreen', 'cake': 'sapgreen', 'book': 'lawngreen', 'potted plant': 'greenyellow', 'toaster': 'ivory', 'stop sign': 'beige', 'couch': 'khaki'} resized = False def forSecond(frame2_number, output_arrays, count_arrays, average_count, returned_frame): plt.clf() this_colors = [] labels = [] sizes = [] counter = 0 for eachItem in average_count: counter += 1 labels.append(eachItem + " = " + str(average_count[eachItem])) sizes.append(average_count[eachItem]) this_colors.append(color_index[eachItem]) global resized if (resized == False): manager = plt.get_current_fig_manager() manager.resize(width=1000, height=500) resized = True plt.subplot(1, 2, 1) plt.title("Second : " + str(frame_number)) plt.axis("off") plt.imshow(returned_frame, interpolation="none") plt.subplot(1, 2, 2) plt.title("Analysis: " + str(frame_number)) plt.pie(sizes, labels=labels, colors=this_colors, shadow=True, startangle=140, autopct="%1.1f%%") plt.pause(0.01) video_detector = VideoObjectDetection() video_detector.setModelTypeAsYOLOv3() video_detector.setModelPath(os.path.join(execution_path, "yolov3.pt")) video_detector.loadModel() plt.show() video_detector.detectObjectsFromVideo(input_file_path=os.path.join(execution_path, "traffic.mp4"), output_file_path=os.path.join(execution_path, "video_second_analysis") , frames_per_second=20, per_second_function=forSecond, minimum_percentage_probability=30, return_detected_frame=True, log_progress=True)—parameter per_minute_function (optional ) : This parameter allows you to parse in the name of a function you define. Then, for every frame of the video that is detected, the function which was parsed into the parameter will be executed and analytical data of the video will be parsed into the function. The data returned has the same nature as the per_second_function ; the difference is that it covers all the frames in the past 1 minute of the video.
See a sample funtion for this parameter below:
def forMinute(minute_number, output_arrays, count_arrays, average_output_count): print("MINUTE : ", minute_number) print("Array for the outputs of each frame ", output_arrays) print("Array for output count for unique objects in each frame : ", count_arrays) print("Output average count for unique objects in the last minute: ", average_output_count) print("------------END OF A MINUTE --------------")—parameter video_complete_function (optional ) : This parameter allows you to parse in the name of a function you define. Once all the frames in the video is fully detected, the function will was parsed into the parameter will be executed and analytical data of the video will be parsed into the function. The data returned has the same nature as the per_second_function and per_minute_function ; the differences are that no index will be returned and it covers all the frames in the entire video.
See a sample funtion for this parameter below:
def forFull(output_arrays, count_arrays, average_output_count): print("Array for the outputs of each frame ", output_arrays) print("Array for output count for unique objects in each frame : ", count_arrays) print("Output average count for unique objects in the entire video: ", average_output_count) print("------------END OF THE VIDEO --------------")—parameter detection_timeout (optional) : This function allows you to state the number of seconds of a video that should be detected after which the detection function stop processing the video.
See a sample code for this parameter below:
from imageai.Detection import VideoObjectDetection import os import cv2 execution_path = os.getcwd() camera = cv2.VideoCapture(0) detector = VideoObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath(os.path.join(execution_path , "retinanet_resnet50_fpn_coco-eeacb38b.pth")) detector.loadModel() video_path = detector.detectObjectsFromVideo(camera_input=camera, output_file_path=os.path.join(execution_path, "camera_detected_video") , frames_per_second=20, log_progress=True, minimum_percentage_probability=40, detection_timeout=120)